
[Nhập môn Machine Learning] Bài 4: Tìm hiểu sâu hơn về Cost Function

Nhắc lại các khái niệm
Ở bài trước, chúng ta đã biết đến Hypothesis Function và Cost Function trong Linear Regression. Hypothesis Function chính là công cụ để giúp những chương trình Machine Learning dự đoán và tìm các trọng số tối ưu thông qua Cost Function sẽ giúp các dự đoán này chính xác hơn.
Vật nên ở bài viết lần này, tôi muốn đưa ra các ví dụ cụ thể để giúp các bạn hình dung rõ hơn hoạt động của 2 hàm này (đặc biệt là Cost Function) và cách chúng tác động với nhau như thế nào.
Tôi đã chuẩn bị sẵn một Dataset gồm các điểm dữ liệu khác nhau, bạn có thể hình dung nó biểu thị cho bất cứ dữ liệu nào ngoài thực tế ( giá nhà theo số mét vuông, tiền trong tài khoản ngân hàng của bạn theo năm,...) để làm cho tư duy của bạn được sinh động hơn thông suốt bài viết.

Có lẽ bạn đã nhận ra mối quan hệ giữa các dữ liệu trên là tuyến tính vì có vẻ như khi $x$ của chúng ta càng tăng thì $y$ cũng tăng theo. Đây là một trường hợp hoàn hảo để áp dụng Linear Regression.
Đầu tiên, ta cần phải lập Hypothesis Function phù hợp với Dataset của chúng ta. Do ở đây dữ liệu của chúng ta chỉ dự đoán dựa trên một tham số $x$ nên $h_\theta(x)$ sẽ có dạng:
\[h_\theta=\theta_0+\theta_1 x\]
Nhưng nó vẫn chưa hoàn chỉnh, chúng ta cần kiếm các trọng số ($\theta_0$, $\theta_1$) phù hợp để thuật toán của ta có thể đưa ra dự đoán chuẩn xác. Như bạn có thể nhớ lại từ bài trước, trong trường hợp này $h_\theta(x)$ chính là phương trình đường thẳng trong không gian hai chiều mà ta đã học ở phổ thông. Trong đó, $\theta_0$ có vai trò dịch chuyển đường thẳng lên xuống theo trục $Oy$, $\theta_1$ là cho độ dốc của đường thẳng mà chúng ta muốn biểu thị. Hai tham số này kết hợp lại có đủ khả năng biểu thị mọi đường thẳng trong không gian hai chiều.
Mục đích chính của thuật toán Linear Regression là tìm một đường thẳng sao cho khoảng cách từ đường thẳng đó đến tất cả các điểm dữ liệu là nhỏ nhất. Tôi gọi các trọng số thỏa mãn yêu cầu này là các trọng số tối ưu.
Cá nhân chúng ta, là người lập trình, không thể mò các trọng số này bằng cảm tính. Nếu bạn muốn làm vậy thì chắc bạn đã không ở đây. Thêm nữa, điều này sẽ càng bất khả thi khi số chiều không gian tăng lên, như 4D chẳng hạn.
Và đây là lúc Cost Function nhảy vào giúp đỡ. dựa trên $h_\theta(x)$ mà ta chọn ở trên. Công thức của Cost Function sẽ được biểu thị dưới dạng:
\[\begin{align*}
J(\theta) &= \frac{1}{2m}\sum_{i=1}^{m}( h_\theta(x^{(i)}) - y^{(i)} )^2 \\
J(\theta_0,\theta_1) &= \frac{1}{2m}\sum_{i=1}^{m}(\theta_0+\theta_1x^{(i)}-y^{(i)})^2\\
J(\theta_0,\theta_1) &= \frac{1}{8}\sum_{i=1}^{4}(\theta_0+\theta_1x^{(i)}-y^{(i)})^2
\end{align*}\]
Ký hiệu $m$ dùng để chỉ số lượng dữ liệu chúng ta có. Ở biểu đồ trên ta có 4 điểm, vậy nên $m=4$. Còn $x^{(i)}, y^{(i)}$ là dữ liệu thứ $i$ trong Dataset của ta, ví dụ như bạn có thể tham khảo ở bảng dưới $x^{(1)}$ của ta là $3.0$ còn $y^{(1)}$ là $1.5$. Hai dấu ngoặc đơn được thêm vào giúp ta không bị nhầm lẫn với phép lũy thừa.

Bây giờ việc cần làm là tìm các trọng số làm cho $J(\theta)$ nhỏ nhất. Các bạn nên để ý rằng các tham số $x$ và $y$ trong Cost Function đều chỉ là các con số cụ thể được lấy ra từ dữ liệu của ta. Điều này khiến cho $J(\theta)$ chỉ phụ thuộc và các trọng số $\theta_0$ và $\theta_1$.Như tôi đã nói ở bài trước, bây giờ ta chỉ cần tìm nơi mà $J(\theta)$ đạt giá trị nhỏ nhất, áp dụng phương pháp tìm giá trị nhỏ nhất trong một hàm số ta đã học từ phổ thông. (tôi mong bạn vẫn còn nhớ)

Không khó để được rằng $J(x)$ chỉ có một điểm cực trị và tại cực trị này giá trị của hàm số là nhỏ nhất. Điều này vẫn đúng dù chúng ta có bao nhiêu trọng số $\theta$ đi chăng nữa.
Để đề phòng các bạn chưa biết khái niệm đạo hàm của hàm số nhiều biến, tạm thời tôi sẽ cho $\theta_0=0$ nhằm tạo ra một phương trình với một trọng số duy nhất. Còn tại sao lại là 0 thì có vẻ bạn cũng ước tính được rằng đường thẳng đẹp nhất so với các điểm dữ liệu của chúng ta sẽ đi qua gốc tọa độ hoặc đâu đó gần đấy.

Vậy $h_\theta(x)$ và $J(\theta)$ của tôi sẽ lần lượt trở thành:
\[h_\theta(x)=\theta_1x \]
\[J(\theta_1)=\frac{1}{8}\sum_{i=1}^{4}(\theta_1x^{(i)}-y^{(1)})^2\]
Nhưng Cost Function của chúng ta vẫn chưa ở dạng đầy đủ của nó. Ta cần phải thế các dữ liệu mà ta thu thập được trong Dataset để có thể tính toán. Đây là bảng dữ liệu tôi để lại để bạn có thể dò theo.

\[\begin{equation*}
J(\theta_1)=\frac{1}{8}\Bigg( \Big(3\cdot\theta_1-1.5\Big)^2 + \Big(5\cdot\theta_1-2.25\Big)^2 + \Big(3.25\cdot\theta_1-1.625\Big)^2 + \Big(1.5\cdot\theta_1-1\Big)^2 \Bigg)
\end{equation*}\]
Việc đầu tiên để tìm được giá trị nhỏ nhất, cũng chính là cực trị duy nhất, của Cost Function là lấy đạo của hàm $J(\theta_1)$ theo $\theta_1$. Bạn có thể tự làm điều này nếu bạn muốn. Còn không, bạn có thể xem tôi làm việc đó bên dưới.
\[\begin{equation*}
\begin{split}
\frac{d\ J(\theta_1)}{d\theta_1} &=\frac{2}{8}\Bigg(3\cdot\Big(3\cdot\theta_1-1.5\Big) +5\cdot\Big(5\cdot\theta_1-2.25\Big)+ 3.25\cdot\Big(3.25\cdot\theta_1-1.625\Big)+1.5\cdot\Big(1.5\cdot\theta_1-0.75\Big)\Bigg)\\
&=\frac{1}{4}\Bigg(\Big(9\cdot\theta_1-4.5\Big)+\Big(25\cdot\theta_1-11.25\Big)+\Big(10.56\cdot\theta_1-5.28\Big)+\Big(2.25\cdot\theta_1-1.125\Big)\Bigg)\\
&=\frac{1}{4}\Bigg(46.81\cdot\theta_1-22.155\Bigg)
\end{split}
\end{equation*}\]
Cho $\dfrac{d\ J(\theta_1)}{d\theta_1}\ =\ 0$ và ta có:
\[\begin{align*}
\frac{d\ J(\theta_1)}{d\theta_1}&=\ 0\\
\frac{1}{4}\cdot\Bigg(46.81\cdot\theta_1-22.155\Bigg)&=\ 0\\
\theta_1&=\ \frac{22.155}{46.81}\\
\theta_1&\approx \ 0.5
\end{align*}\]
Vậy trọng số tối ưu có giá trị $\theta_1=0.5$. Lúc này, đường thẳng chúng ta có được là:
 Khá là tuyệt vời đúng không? Chỉ bằng những tính toán thông thường bạn đã có thể tìm ra trọng số tối ưu mà không cần ước chừng một cách thủ công. Thật ra do chúng ta đã làm tròn trọng số này nên đã có một vài thông tin bị mất đi, dù cho các thông tin đó là rất nhỏ. Tuy nhiên, nếu tôi để máy tính đảm nhiệm công việc tính toán giúp tôi, việc chúng làm tốt nhất, ta có thể ra được kết quả tốt hơn.
Khá là tuyệt vời đúng không? Chỉ bằng những tính toán thông thường bạn đã có thể tìm ra trọng số tối ưu mà không cần ước chừng một cách thủ công. Thật ra do chúng ta đã làm tròn trọng số này nên đã có một vài thông tin bị mất đi, dù cho các thông tin đó là rất nhỏ. Tuy nhiên, nếu tôi để máy tính đảm nhiệm công việc tính toán giúp tôi, việc chúng làm tốt nhất, ta có thể ra được kết quả tốt hơn.


Tôi đã sử dụng Python để tính toán lại những gì chúng ta đã làm. Như các bạn thấy, đường thẳng màu đỏ được vẽ do máy tính có vẻ không được khớp lắm nếu ta nhìn bằng mắt thường nhưng về bản chất toán học, chúng mới là các trọng số tối ưu. Tôi biết rằng khác biệt là không lớn nhưng trên thực tế ta phải làm việc với số lượng dữ liệu lên tới con số hàng trăm (và tin tôi đi, chúng sẽ không "đẹp" như dữ liệu của chúng ta đâu) khiến việc lợi dụng ưu điểm tính toán của máy tính (nhanh và chính xác) sẽ tốt hơn nhiều.

Thêm nữa, nếu tôi vẽ ra đồ thị của $J(\theta)$ thay đổi theo $\theta$ (tôi xin phép gọi $\theta$ cho ngắn gọn thay vì $\theta_1$) nó sẽ biểu thị đúng những gì tôi đã dự đoán, rằng chỉ có một cực trị và tại vị trí đó, chúng ta sẽ tìm được trọng số tối ưu.
Vật nên ở bài viết lần này, tôi muốn đưa ra các ví dụ cụ thể để giúp các bạn hình dung rõ hơn hoạt động của 2 hàm này (đặc biệt là Cost Function) và cách chúng tác động với nhau như thế nào.
Tôi đã chuẩn bị sẵn một Dataset gồm các điểm dữ liệu khác nhau, bạn có thể hình dung nó biểu thị cho bất cứ dữ liệu nào ngoài thực tế ( giá nhà theo số mét vuông, tiền trong tài khoản ngân hàng của bạn theo năm,...) để làm cho tư duy của bạn được sinh động hơn thông suốt bài viết.

Đầu tiên, ta cần phải lập Hypothesis Function phù hợp với Dataset của chúng ta. Do ở đây dữ liệu của chúng ta chỉ dự đoán dựa trên một tham số $x$ nên $h_\theta(x)$ sẽ có dạng:
\[h_\theta=\theta_0+\theta_1 x\]
Nhưng nó vẫn chưa hoàn chỉnh, chúng ta cần kiếm các trọng số ($\theta_0$, $\theta_1$) phù hợp để thuật toán của ta có thể đưa ra dự đoán chuẩn xác. Như bạn có thể nhớ lại từ bài trước, trong trường hợp này $h_\theta(x)$ chính là phương trình đường thẳng trong không gian hai chiều mà ta đã học ở phổ thông. Trong đó, $\theta_0$ có vai trò dịch chuyển đường thẳng lên xuống theo trục $Oy$, $\theta_1$ là cho độ dốc của đường thẳng mà chúng ta muốn biểu thị. Hai tham số này kết hợp lại có đủ khả năng biểu thị mọi đường thẳng trong không gian hai chiều.
Mục đích chính của thuật toán Linear Regression là tìm một đường thẳng sao cho khoảng cách từ đường thẳng đó đến tất cả các điểm dữ liệu là nhỏ nhất. Tôi gọi các trọng số thỏa mãn yêu cầu này là các trọng số tối ưu.
Cá nhân chúng ta, là người lập trình, không thể mò các trọng số này bằng cảm tính. Nếu bạn muốn làm vậy thì chắc bạn đã không ở đây. Thêm nữa, điều này sẽ càng bất khả thi khi số chiều không gian tăng lên, như 4D chẳng hạn.
Và đây là lúc Cost Function nhảy vào giúp đỡ. dựa trên $h_\theta(x)$ mà ta chọn ở trên. Công thức của Cost Function sẽ được biểu thị dưới dạng:
\[\begin{align*}
J(\theta) &= \frac{1}{2m}\sum_{i=1}^{m}( h_\theta(x^{(i)}) - y^{(i)} )^2 \\
J(\theta_0,\theta_1) &= \frac{1}{2m}\sum_{i=1}^{m}(\theta_0+\theta_1x^{(i)}-y^{(i)})^2\\
J(\theta_0,\theta_1) &= \frac{1}{8}\sum_{i=1}^{4}(\theta_0+\theta_1x^{(i)}-y^{(i)})^2
\end{align*}\]
Ký hiệu $m$ dùng để chỉ số lượng dữ liệu chúng ta có. Ở biểu đồ trên ta có 4 điểm, vậy nên $m=4$. Còn $x^{(i)}, y^{(i)}$ là dữ liệu thứ $i$ trong Dataset của ta, ví dụ như bạn có thể tham khảo ở bảng dưới $x^{(1)}$ của ta là $3.0$ còn $y^{(1)}$ là $1.5$. Hai dấu ngoặc đơn được thêm vào giúp ta không bị nhầm lẫn với phép lũy thừa.

Bây giờ việc cần làm là tìm các trọng số làm cho $J(\theta)$ nhỏ nhất. Các bạn nên để ý rằng các tham số $x$ và $y$ trong Cost Function đều chỉ là các con số cụ thể được lấy ra từ dữ liệu của ta. Điều này khiến cho $J(\theta)$ chỉ phụ thuộc và các trọng số $\theta_0$ và $\theta_1$.Như tôi đã nói ở bài trước, bây giờ ta chỉ cần tìm nơi mà $J(\theta)$ đạt giá trị nhỏ nhất, áp dụng phương pháp tìm giá trị nhỏ nhất trong một hàm số ta đã học từ phổ thông. (tôi mong bạn vẫn còn nhớ)
Đi tìm trọng số tối ưu
Để tìm được giá trị nhỏ nhất trong một hàm, ta cần lấy giá trị của hàm tại các điểm cực trị, nơi đạo hàm của nó bằng không và so sánh với giá trị hai biên.
Nhưng Cost Function của chúng ta chỉ là tổng của nhiều hàm bậc hai dương khác nhau. Ở bên dưới là một hình ảnh của hàm số $y=x^2$ là một hàm số bậc hai dương.

Để đề phòng các bạn chưa biết khái niệm đạo hàm của hàm số nhiều biến, tạm thời tôi sẽ cho $\theta_0=0$ nhằm tạo ra một phương trình với một trọng số duy nhất. Còn tại sao lại là 0 thì có vẻ bạn cũng ước tính được rằng đường thẳng đẹp nhất so với các điểm dữ liệu của chúng ta sẽ đi qua gốc tọa độ hoặc đâu đó gần đấy.

Vậy $h_\theta(x)$ và $J(\theta)$ của tôi sẽ lần lượt trở thành:
\[h_\theta(x)=\theta_1x \]
\[J(\theta_1)=\frac{1}{8}\sum_{i=1}^{4}(\theta_1x^{(i)}-y^{(1)})^2\]
Nhưng Cost Function của chúng ta vẫn chưa ở dạng đầy đủ của nó. Ta cần phải thế các dữ liệu mà ta thu thập được trong Dataset để có thể tính toán. Đây là bảng dữ liệu tôi để lại để bạn có thể dò theo.

\[\begin{equation*}
J(\theta_1)=\frac{1}{8}\Bigg( \Big(3\cdot\theta_1-1.5\Big)^2 + \Big(5\cdot\theta_1-2.25\Big)^2 + \Big(3.25\cdot\theta_1-1.625\Big)^2 + \Big(1.5\cdot\theta_1-1\Big)^2 \Bigg)
\end{equation*}\]
Việc đầu tiên để tìm được giá trị nhỏ nhất, cũng chính là cực trị duy nhất, của Cost Function là lấy đạo của hàm $J(\theta_1)$ theo $\theta_1$. Bạn có thể tự làm điều này nếu bạn muốn. Còn không, bạn có thể xem tôi làm việc đó bên dưới.
\[\begin{equation*}
\begin{split}
\frac{d\ J(\theta_1)}{d\theta_1} &=\frac{2}{8}\Bigg(3\cdot\Big(3\cdot\theta_1-1.5\Big) +5\cdot\Big(5\cdot\theta_1-2.25\Big)+ 3.25\cdot\Big(3.25\cdot\theta_1-1.625\Big)+1.5\cdot\Big(1.5\cdot\theta_1-0.75\Big)\Bigg)\\
&=\frac{1}{4}\Bigg(\Big(9\cdot\theta_1-4.5\Big)+\Big(25\cdot\theta_1-11.25\Big)+\Big(10.56\cdot\theta_1-5.28\Big)+\Big(2.25\cdot\theta_1-1.125\Big)\Bigg)\\
&=\frac{1}{4}\Bigg(46.81\cdot\theta_1-22.155\Bigg)
\end{split}
\end{equation*}\]
Cho $\dfrac{d\ J(\theta_1)}{d\theta_1}\ =\ 0$ và ta có:
\[\begin{align*}
\frac{d\ J(\theta_1)}{d\theta_1}&=\ 0\\
\frac{1}{4}\cdot\Bigg(46.81\cdot\theta_1-22.155\Bigg)&=\ 0\\
\theta_1&=\ \frac{22.155}{46.81}\\
\theta_1&\approx \ 0.5
\end{align*}\]
Vậy trọng số tối ưu có giá trị $\theta_1=0.5$. Lúc này, đường thẳng chúng ta có được là:


Tôi đã sử dụng Python để tính toán lại những gì chúng ta đã làm. Như các bạn thấy, đường thẳng màu đỏ được vẽ do máy tính có vẻ không được khớp lắm nếu ta nhìn bằng mắt thường nhưng về bản chất toán học, chúng mới là các trọng số tối ưu. Tôi biết rằng khác biệt là không lớn nhưng trên thực tế ta phải làm việc với số lượng dữ liệu lên tới con số hàng trăm (và tin tôi đi, chúng sẽ không "đẹp" như dữ liệu của chúng ta đâu) khiến việc lợi dụng ưu điểm tính toán của máy tính (nhanh và chính xác) sẽ tốt hơn nhiều.
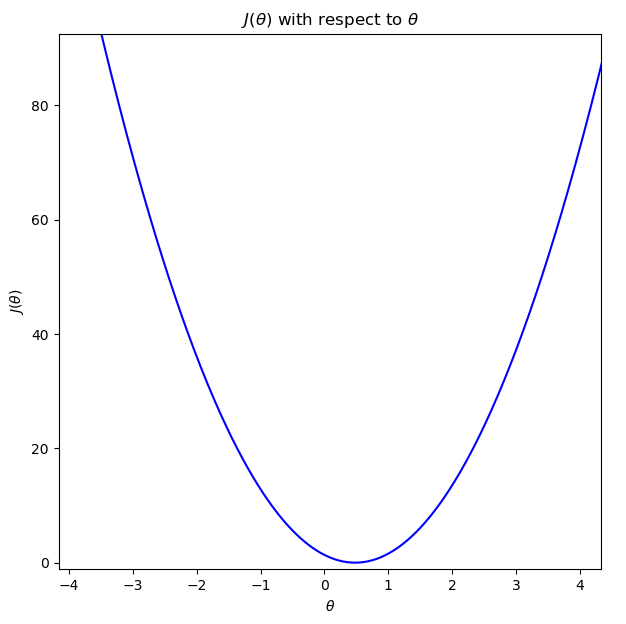
Thêm nữa, nếu tôi vẽ ra đồ thị của $J(\theta)$ thay đổi theo $\theta$ (tôi xin phép gọi $\theta$ cho ngắn gọn thay vì $\theta_1$) nó sẽ biểu thị đúng những gì tôi đã dự đoán, rằng chỉ có một cực trị và tại vị trí đó, chúng ta sẽ tìm được trọng số tối ưu.
Nhưng máy tính đâu phải là tôi!!
Bạn có thể phản biện lại rằng - "Ừ, đúng thật đấy. Nhưng việc lấy đạo hàm là do tôi làm mà!"
Máy tính có thể nhanh ở các tính toán truyền thống. Thế nhưng những tính toán, quy tắc dựa trên khái niệm như đạo hàm, thế số, chuyển vế đổi dấu vốn được phát minh ra là dành cho con người thì sao? Chẳng lẽ mỗi lần làm Linear Regression tôi lại phải ngồi lấy đạo hàm sau đó "nhét" cái công thức tôi dùng để tính $\theta$ vào máy tính? (Vậy thì thật là bất tiện)
Thật sự thì bạn không cần phải làm thế. Ở bài viết sau tôi sẽ đề cập đến một thuật toán mới giúp máy tính của chúng ta (những cỗ máy ngu ngốc chỉ biết làm theo những mã lệnh khô cứng) có thể tự làm việc này mà không cần sự giúp sức của chúng ta.



bài viết hay quá ạ
Trả lờiXóahay quá ạ. Cảm ơn bạn
Trả lờiXóabai viet hay that su,, rat de hieu,, thanks ban
Trả lờiXóaBài viết đã cho em cái nhìn rất tổng quan về Linear Regression. Cảm ơn tác giả.
Trả lờiXóahay quá ,mong bạn viết thêm vài bài hữu ít như vầy nửa ,cảm ơn bạn
Trả lờiXóaEm nghĩ anh nên thêm hình vẽ hiển thị rõ phần lệch y so với đường thẳng đi xuyên qua các điểm để từ đó mọi người sẽ dễ hiểu hơn vì sao công thức tính cost function nó lại là tổng các chênh lệch bình phương chia cho 2m ạ
Trả lờiXóa"Cùng tìm hiểu thêm về machine learning nhé!
Trả lờiXóamachine learning là gì"